编码与解码
什么是编码与解码
电脑是由电路板组成,电路板里面集成了无数的电阻和电容, 交流电经过电容的时候,电压比较低 记为低电平 ,用0表示,交流电流过电阻的时候,电压比较高,记为高电平,用1来表示; 所以每一个1 和0 在计算机中被称为 位,也就是bit位。然而,如果使用一个位来表示计算机中的最小存储单元, 那么这个存储单元只能存储0或者1,存储的范围太小了,所以我们规定用用8个bit位为一组 来表示 计算机的最小存储单元。 8个位 每个位上能存储0或者1,则byte的存储范围则是 00000000-11111111(换算成整数即0-255)。 这个最小存储单元 就是byte 字节。
计算机的底层只能存储0和1,如果是日常生活中遇到的数字 比如 127 ,这个可以通过10进制和二进制的转换从而让计算机存储01111111,但是如果计算机存储类似于汉字、英文字符、符号字符等内容,是如何存储的呢?
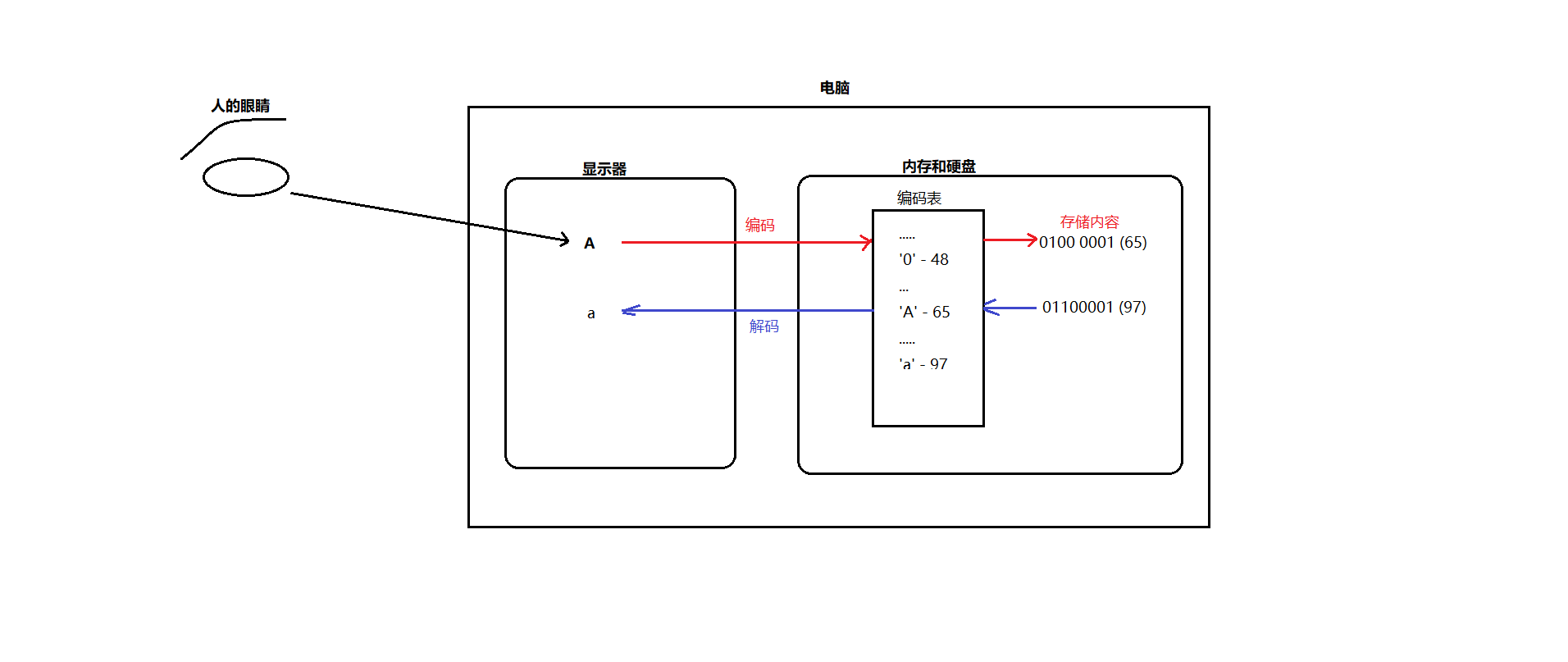
根据上图解释说明,计算机提供了很多的编码表记录了字符和数字的一一对应关系,编码就是把字符对应编码表中的码值存储在电脑中,而解码则是把码值在编码表中的对应的字符展现出来。
1 | 注意:计算机中存储一个数 是用二进制来表示的,比如 存储127,那么计算机的底层是 0111 1111,人看这些二进制的数通常都是眼花缭乱的,如何方便而规整的表示这些二进制数呢,不妨引入十六进制。二进制换算成十六进制,则是每四位为一组转换为16进制数即可, 比如0111 1111 这个数前4位 0111 转换为 7 , 后4位转换为F, 则最终的16进制数是 7F,一般我繁琐的二进制数使用十六进制数来表示会比较方便规整,所以人们习惯用十六进制数来表示码值。 |
计算机提供了哪些编码表呢?
常见的编码表
ASCII
世界上虽然有各种各样的字符,但计算机发明之初没有考虑那么多,基本上只考虑了美国的需求,美国大概只需要128个字符,美国就规定了这128个字符的二进制表示方法,这个方法是一个标准,称为ASCII编码,全称是American Standard Code for Information Interchange,美国信息互换标准代码。128个字符用7个位刚好可以表示,计算机存储的最小单位是byte,即8位,ASCII码中最高位设置为0,用剩下的7位表示字符。这7位可以看做数字0到127,ASCII码规定了从0到127个,每个数字代表什么含义。我们先来看数字32到126的含义,如下图所示,除了中文之外,我们平常用的字符基本都涵盖了,键盘上的字符大部分也都涵盖了。
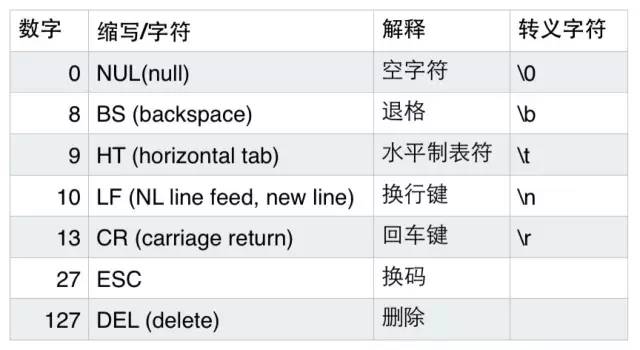
数字32到126表示的这些字符都是可打印字符,0到31和127表示一些不可以打印的字符,这些字符一般用于控制目的,这些字符中大部分都是不常用的,下表列出了其中相对常用的字符。
Ascii码对美国是够用了,但对别的国家而言却是不够的,于是,各个国家的各种计算机厂商就发明了各种各样的编码方式以表示自己国家的字符,为了保持与Ascii码的兼容性,一般都是将最高位设置为1。也就是说,当最高位为0时,表示Ascii码,当为1时就是各个国家自己的字符。在这些扩展的编码中,在西欧国家中流行的是ISO 8859-1和Windows-1252,在中国是GB2312,GBK,GB18030和Big5,我们逐个来研究这些编码。
ISO-8859-1
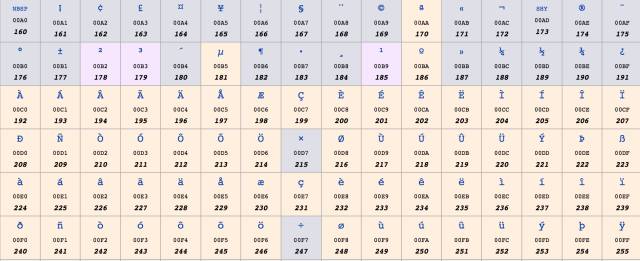
ISO 8859-1又称Latin-1,它也是使用一个字节表示一个字符,因为西欧的文字也都是字母拼接,只不过不是26个英文字母罢了,其中0到127与Ascii一样,128到255规定了不同的含义。在128到255中,128到159表示一些控制字符,这些字符也不常用,就不介绍了。160到255表示一些西欧字符,如下图所示:
windows-1252
ISO 8859-1虽然号称是标准,用于西欧国家,但它连欧元(€) 这个符号都没有,因为欧元比较晚,而标准比较早。实际使用中更为广泛的是Windows-1252编码,这个编码与ISO8859-1基本是一样的,区别 只在于数字128到159,Windows-1252使用其中的一些数字表示可打印字符,这些数字表示的含义,如下图所示:

这个编码中加入了欧元符号以及一些其他常用的字符。基本上可以认为,ISO 8859-1已被Windows-1252取代,在很多应用程序中,即使文件声明它采用的是ISO 8859-1编码,解析的时候依然被当做Windows-1252编码。
HTML5 甚至明确规定,如果文件声明的是ISO 8859-1编码,它应该被看做Windows-1252编码。为什么要这样呢?因为大部分人搞不清楚ISO 8859-1和Windows-1252的区别,当他说ISO 8859-1的时候,其实他实际指的是Windows-1252,所以标准干脆就这么强制了。
GB2312
美国和西欧字符用一个字节就够了,但中文显然是不够的。中文第一个标准是GB2312。GB2312标准主要针对的是简体中文常见字符,包括约7000个汉字,不包括一些罕见词,不包括繁体字。GB2312固定使用两个字节表示汉字,在这两个字节中,最高位都是1,如果是0,就认为是Ascii字符。在这两个字节中,其中第一个字节范围是1010 0001(十进制161) - 1111 0111(十进制247),第二个字节范围是1010 0001(十进制161) - 1111 1110(十进制254)。
比如,”贤哥”的GB2312编码是
| 贤 | 哥 |
|---|---|
| CF, CD | B8 , E7 |
为了方便的查看二进制 和 十进制 和 十六进制的转换 ,可以使用下面的两个方法。
1 | /** |
GBK
GBK建立在GB2312的基础上,向下兼容GB2312,也就是说,GB2312编码的字符的二进制表示,在GBK编码里是完全一样的。GBK增加了一万四千多个汉字,共计约21000汉字,其中包括繁体字。GBK同样使用固定的两个字节表示,其中第一个字节范围是1000 0001(十进制129) - 1111 1110(十进制254),第二个字节范围是0100 0000(十进制64) - 0111 1110(十进制126)和1000 0000(十进制128) - 1111 1110(十进制254)。
需要注意的是,第二个字节是从64开始的(64属于byte正数范围,和ASCII的编码重合了),也就是说,第二个字节最高位可能为0。那怎么知道它是汉字的一部分,还是一个ASCII字符呢?
其实很简单,因为汉字是用固定两个字节表示的,在解析二进制流的时候,如果第一个字节的最高位为1,那么就将下一个字节读进来一起解析为一个汉字,而不用考虑它的最高位,解析完后,跳到第三个字节继续解析。
GB18030
GB18030向下兼容GBK,增加了五万五千多个字符,共七万六千多个字符。包括了很多少数民族字符,以及中日韩统一字符。用两个字节已经表示不了GB18030中的所有字符,GB18030使用变长编码,有的字符是两个字节,有的是四个字节。在两字节编码中,字节表示范围与GBK一样。在四字节编码中,第一个字节的值从1000 0001(十进制129) 到11111110(十进制254),第二个字节的值从0011 0000(十进制48)到0011 1001(十进制57),第三个字节的值从1000 0001(十进制129) 到11111110(十进制254),第四个字节的值从0011 0000(十进制48)到0011 1001(十进制57)。
解析二进制时,如何知道是两个字节还是四个字节表示一个字符呢?很简单,看第二个字节的范围,如果是48到57就是四个字节表示,因为两个字节编码中第二字节都比这个大。所以这样综合说明GB18030兼容GBK,兼容GB2312,兼容ASCII,但是GB18030,GBK,GB2312这三个编码和ISO8859-1是不兼容的哦。
Big5
Big5是针对繁体中文的,广泛用于台湾香港等地。Big5包括1万3千多个繁体字,和GB2312类似,一个字符同样固定使用两个字节表示。在这两个字节中,第一个字节范围是10000001(十进制129) 到1111 1110(十进制254),第二个字节范围是0100 0000(十进制64) - 0111 1110(十进制126) 和1010 0001(十进制161) - 1111 1110(十进制254)。Big5和GB18030,GBK,GB2312不兼容哈,如果已经理解了上文,其实你就能理解为什么Big5和GB的三个编码为什么不兼容了。
编码表汇总
我们简单汇总一下上面的内容。Ascii码是基础,一个字节表示,最高位设为0,其他7位表示128个字符。其他编码都是兼容Ascii的,最高位使用1来进行区分。西欧主要使用Windows-1252,使用一个字节,增加了额外128个字符。中文大陆地区的三个主要编码GB2312,GBK,GB18030,有时间先后关系,表示的字符数越来越多,且后面的兼容前面的,GB2312和GBK都是用两个字节表示,而GB18030则使用两个或四个字节表示。香港台湾地区的主要编码是Big5。
如果文本里的字符都是Ascii码字符,那么采用以上所说的任一编码方式都是一样的,不会乱码。但如果有高位为1的字符,除了GB2312/GBK/GB18030外,其他编码都是不兼容的,比如,Windows-1252和中文的各种编码是不兼容的,即使Big5和GB18030都能表示繁体字,其表示方式也是不一样的,而这就会出现所谓的乱码。
乱码和兼容
兼容:GB2312/GBK/GB18030 ASCII是兼容的 比如我们文本里面 a字符,使用这四种码表任何一种都是可以正常显示的。
windows-1252和ISO-8859-1 和ASCII是兼容的
Big5和ASCII是兼容的
但是 西欧编码 和 Big5 以及 GB系列的编码 他们相互之间是不兼容的,也就是 同样的码值在三种编码表中显示的内容是不一样的。
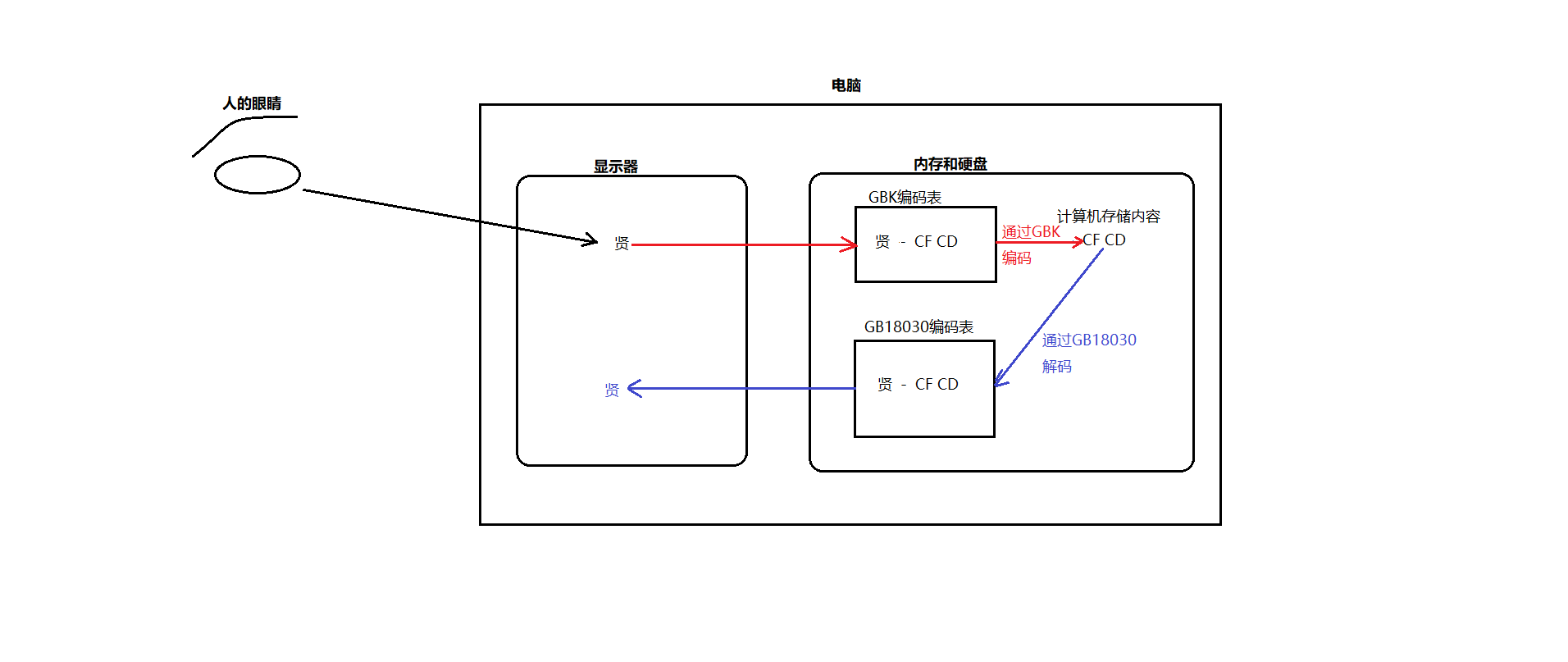
乱码:如果编码的时候同一种编码表,而解码的时候通过的却是一种不兼容的编码表,则就就会出现乱码现象。
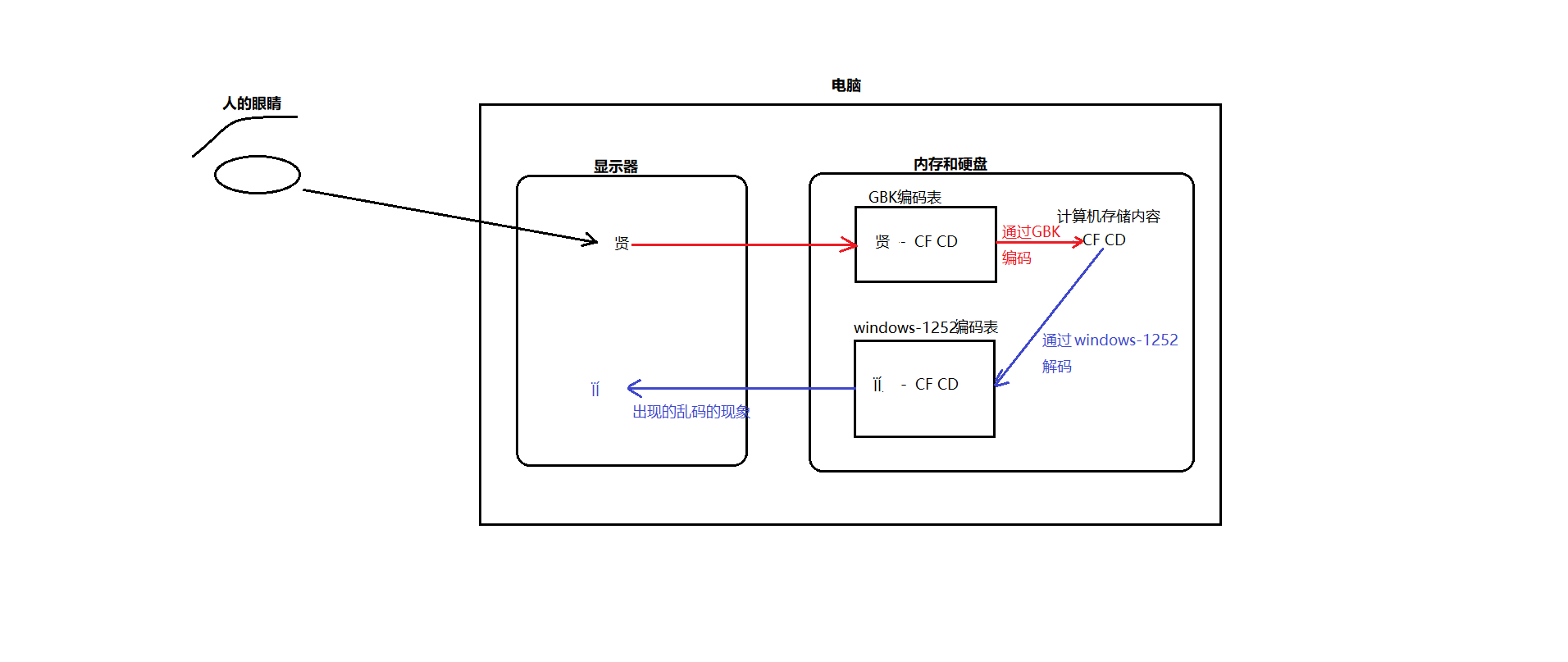
Unicode
以上我们介绍了中文和西欧的字符与编码,但世界上还有很多的国家的字符,每个国家的各种计算机厂商都对自己常用的字符进行编码,在编码的时候基本忽略了别的国家的字符和编码,甚至忽略了同一国家的其他计算机厂商,这样造成的结果就是,出现了太多的编码,且互相不兼容。
世界上所有的字符能不能统一编码呢?可以,这就是Unicode。
Unicode 做了一件事,就是给世界上所有字符都分配了一个唯一的数字编号,这个编号范围从0x000000到0x10FFFF,包括110多万。但大部分常用字符都 在0x0000到0xFFFF之间,即65536个数字之内。每个字符都有一个Unicode编号,这个编号一般写成16进制,在前面加U+。大部分中文 的编号范围在U+4E00到U+9FA5,例如,”贤”的Unicode是U+8D24。
Unicode就做了这么 一件事,就是给所有字符分配了唯一数字编号。它并没有规定这个编号怎么对应到二进制表示,这是与上面介绍的其他编码不同的,其他编码都既规定了能表示哪些 字符,又规定了每个字符对应的二进制是什么,而Unicode本身只规定了每个字符的数字编号是多少。
1 | 1990年开始研发,1994年正式公布。随着计算机工作能力的增强,Unicode也在面世以来的十多年里得到普及。 |
那编号怎么对应到二进制表示呢?有多种方案,主要有UTF-32, UTF-16和UTF-8。
UTF-32
这个最简单,就是字符编号的整数二进制形式,四个字节。
但有个细节,就是字节的排列顺序,如果第一个字节是整数二进制中的最高位,最后一个字节是整数二进制中的最低位,那这种字节序就叫“大端”(Big Endian, BE),否则,正好相反的情况,就叫“小端”(Little Endian, LE)。对应的编码方式分别是UTF-32BE和UTF-32LE。比如
| Unicode编码 | UTF32-LE | UTF32-BE |
|---|---|---|
| 0x006C49 | 49 6C 00 00 | 00 00 6C 49 |
| 0x020C30 | 30 0C 02 00 | 00 02 0C 30 |
1 | 注意:之所以有大端和小端两种方式,是因为硬件读写顺序的不同。 |
可以看出,每个字符都用四个字节表示,非常浪费空间,实际采用的也比较少。
1 | 注意:UTF-32是因为UTF-16编码方式不能表示全部的字符而扩充的编码方式 |
UTF-16
在了解 UTF-16 编码方式之前,先了解一下另外一个概念——“平面”。
在上面的介绍中,提到了 Unicode 是一本很厚的字典,她将全世界所有的字符定义在一个集合里。这么多的字符不是一次性定义的,而是分区定义。每个区可以存放 65536 个(2^16)字符,称为一个平面(plane)。目前,一共有 17 个(2^5)平面(65536*17 = 1,114,112 也就是110多万),也就是说,整个 Unicode 字符集的大小现在是 2^21。
最前面的 65536 个字符位,称为基本平面(简称 BMP ),它的码点范围是从 0 到 2^16-1,写成 16 进制就是从 U+0000 到 U+FFFF。所有最常见的字符都放在这个平面,这是 Unicode 最先定义和公布的一个平面。剩下的字符都放在辅助平面(简称 SMP ),码点范围从 U+010000 到 U+10FFFF。
基本了解了平面的概念后,再说回到 UTF-16。UTF-16 编码介于 UTF-32 与 UTF-8 之间,同时结合了定长和变长两种编码方法的特点。它的编码规则很简单:基本平面的字符占用 2 个字节,辅助平面的字符占用 4 个字节。也就是说,UTF-16 的编码长度要么是 2 个字节(U+0000 到 U+FFFF,也就是),要么是 4 个字节(U+010000 到 U+10FFFF)。那么问题来了,当我们遇到两个字节时,到底是把这两个字节当作一个字符还是与后面的两个字节一起当作一个字符呢?
为了将两个字节的UTF-16编码与四个字节的UTF-16编码区分开来,Unicode编码的设计者将0xD800-0xDFFF保留下来,并称为代理区(Surrogate):
辅助平面的字符位共有 2^20 个,因此表示这些字符至少需要 20 个二进制位。UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF,称为高代理位(H),后 10 位映射在 U+DC00 到 U+DFFF,称为低代理位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。
| D800-DB7F | High Surrogates | 高位替代 |
|---|---|---|
| DC00-DFFF | Low Surrogates | 低位替代 |
如果U≥0x10000,我们先计算U’=U-0x10000,然后将U’写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码(二进制)就是:110110yyyyyyyyyy 110111xxxxxxxxxx。
按照上述规则,Unicode编码0x10000-0x10FFFF的UTF-16编码有四个字节,前两个字节的高6位是110110,后两个字节的高6位是110111。可见,前两个字节的取值范围(二进制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。后两个字节取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。
因此,当我们遇到两个字节,发现它的码点在 U+D800 到 U+DBFF 之间,就可以断定,紧跟在后面的两个字节的码点,应该在 U+DC00 到 U+DFFF 之间,这四个字节必须放在一起解读。
接下来,以汉字”𠮷”为例,说明 UTF-16 编码方式是如何工作的。
汉字”𠮷”的 Unicode 码点为 0x20BB7,该码点显然超出了基本平面的范围(0x0000 - 0xFFFF),因此需要使用四个字节表示。首先用 0x20BB7 - 0x10000 计算出超出的部分,然后将其用 20 个二进制位表示(不足前面补 0 ),结果为0001000010 1110110111。接着,将前 10 位映射到 U+D800 到 U+DBFF 之间,后 10 位映射到 U+DC00 到 U+DFFF 即可。U+D800 对应的二进制数为 1101100000000000,直接填充后面的 10 个二进制位即可,得到 1101100001000010,转成 16 进制数则为 0xD842。同理可得,低位为 0xDFB7。因此得出汉字”𠮷”的 UTF-16 编码为 0xD842 0xDFB7。
和UTF-32一样,UTF-16也有UTF-16LE和UTF-16BE之分,例如:
| Unicode编码 | UTF-16LE | UTF-16BE | UTF32-LE | UTF32-BE |
|---|---|---|---|---|
| 0x006C49 | 49 6C | 6C 49 | 49 6C 00 00 | 00 00 6C 49 |
| 0x020C30 | 30 DC 43 D8 | D8 43 DC 30 | 30 0C 02 00 | 00 02 0C 30 |
1 | 注意:UTF-16常用于系统内部编码,我们平常说的 “Unicode编码是2个字节” 这句话,其实是因为windows系统默认的Unicode编码就是UTF-16,在常用基本字符上2个字节的编码方式已经够用导致的误解,其实是可变长度的。在没有特殊说明的情况下,常说的Unicode编码可以理解为UTF-16编码,而且是UTF-16BE编码 |
UTF-16比UTF-32节省了很多空间,但是任何一个字符都至少需要两个字节表示,对于美国和西欧国家而言,还是很浪费的。
UTF-8
UTF-8就是使用变长字节表示,每个字符使用的字节个数与其Unicode编号的大小有关,编号小的使用的字节就少,编号大的使用的字节就多,使用的字节个数从1到4个不等。
具体来说,各个Unicode编号范围对应的二进制格式如下表所示
| Unicode编码(十六进制) | UTF-8 字节流(二进制) |
|---|---|
| 000000-00007F | 0xxxxxxx |
| 000080-0007FF | 110xxxxx 10xxxxxx |
| 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110xxx10xxxxxx10xxxxxx10xxxxxx |
图中的x表示可以用的二进制位,而每个字节开头的1或0是固定的。
小于128的(即0x00-0x7F之间的字符),编码与Ascii码一样,最高位为0。其他编号的第一个字节有特殊含义,最高位有几个连续的1表示一共用几个字节表示,而其他字节都以10开头。4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
对于一个Unicode编号,具体怎么编码呢?首先将其看做整数,转化为二进制形式(去掉高位的0),然后将二进制位从右向左依次填入到对应的二进制格式x中,填完后,如果对应的二进制格式还有没填的x,则设为0。
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例2:Unicode编码0x20C30在0x010000-0x10FFFF之间,使用4字节模板:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
1 | 注意:UTF-8和UTF-32/UTF-16不同的地方是UTF-8是兼容Ascii的,对大部分中文而言,一个中文字符需要用三个字节表示。UTF-8的优势是网络上数据传输英文字符只需要1个字节,可以节省带宽资源。所以当前大部分的网络应用都使用UTF-8编码,因为网络应用的代码编写全部都是使用的英文编写,占据空间小,网络传输速度快。 |
BOM
我们通常会看到这样的编码 UTF-8和UTF-8+BOM ,那么什么是BOM呢?
比如一个文本软件,在打开一个文件的时候,如何判断这个文件是使用的什么编码呢,该用什么编码进行解码呢?那么就需要通过BOM(Byte Order Mark)来指明了。
Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符“零宽无中断空格”。这个字符的编码是FEFF,而反过来的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。
| UTF编码 | Byte Order Mark (BOM) |
|---|---|
| UTF-8 without BOM | 无 |
| UTF-8 with BOM | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
1 | 注意:UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明文件是UTF-8的编码方式。根据BOM的规则,在一段字节流开始时,如果接收到以下字节,则分别表明了该文本文件的编码。而如果不是以BOM开头,那程序则会以ANSI,也就是系统默认编码读取。 |
乱码的原因和可逆性
乱码原因
乱码产生的根源一般情况下可以归结为三方面即:编码引起的乱码、解码引起的乱码以及缺少某种字体库引起的乱码(这种情况需要用户安装对应的字体库),其中大部分乱码问题是由不合适的解码方式造成的

乱码可逆情况
其中缺少字体,只需要安装对应的字体库即可解决乱码,比如 Windows 系统在 C:\Windows\Fonts 目录下会有安装好的字体库列表。安装字体库比较简单,下载后解压,然后复制到对应系统的 Fonts 目录下。
解码方式和编码方式不一致的情况,只需要让解码方式和编码方式一致即可让乱码恢复。
乱码不可逆情况
GBK编码不支持这几个字符 “𠮷” “♠” “♥” , 如果再一个 GBK编码的文件中,写入 “𠮷” “♠” “♥” 这些字符, 那么他们就会变成??, ?对应的码值是3F,这样的情况就没有办法恢复。 因为 “𠮷”的本来的码值 变成了 两个 3F (即两个问号),无论如何也不能恢复过来了。
Java的char字符
在 Java内部进行字符处理时,采用的都是Unicode,具体编码格式是UTF-16BE。简单回顾一下,UTF-16使用两个或四个字节表示一个字 符,Unicode编号范围在65536以内的占两个字节,超出范围的占四个字节,BE (Big Endian)就是先输出高位字节,再输出低位字节,这与整数的内存表示是一致的。
char本质上是一个固定占用两个字节的无符号正整数,这个正整数对应于Unicode编号,用于表示那个Unicode编号对应的字符。
由于固定占用两个字节,char只能表示Unicode编号在65536以内的字符,而不能表示超出范围的字符。
那超出范围的字符怎么表示呢?只能使用String类来表示,例如汉字”𠮷”的 Unicode 码点为 0x20BB7,该码点显然超出了65535,所只能用String表,而当粘贴到代码中时,自动转换为了两个字符”\uD842\uDFB7”
1 | char c ='味'; |
char有多种赋值方式:
1 | char c = 'A'; |
第1种赋值方式是最常见的,将一个能用Ascii码表示的字符赋给一个字符变量。
第 2种也很常见,但这里是个中文字符,需要注意的是,直接写字符常量的时候应该注意文件的编码,比如说,GBK编码的代码文件按UTF-8打开,字符会变成乱码,所以有的时候为了避免代码中出现的汉字常量乱码 可以使用第5中方式赋值,至于汉字和Unicode的码值转换有很多网站可以做到。比如 百度上搜索 汉字 转换Unicode第一条链接http://www.atool9.com/chinese2unicode.php
第3种是直接将十进制的常量赋给字符,第4种是将16进制常量赋给字符,第5种是按Unicode字符形式。
以上,2,3,4,5都是一样的,本质都是将Unicode编号39532赋给了字符。
char 的加减运算就是按其Unicode编号进行运算,一般对字符做加减运算没什么意义,但Ascii码字符是有意义的。比如大小写转换,大写A-Z的编号是 65-90,小写a-z的编号是97-122,正好相差32,所以大写转小写只需加32,而小写转大写只需减32。加减运算的另一个应用是加密和解密,将 字符进行某种可逆的数学运算可以做加解密。
String类
编码的方法
getBytes()方法
public byte[] getBytes(); 此方法根据java命令运行时参数 file.encoding设置的编码表进行编码的。
1 | String s = "黑马"; |
打印结果是[-23, -69, -111, -23, -87, -84],很明显2个中文6个字节,应该是采用的UTF-8编码,查看getBytes方法的底层发现
1 | class String{ |
经过查看源码,我们发现底层循环默认编码defaultCharset 是根据的 file.encoding,file.encodig 是System类里面的的一次参数,可以通过System类来获取, 通过 java命令运行java程序的时候 -Dfile.encoding=编码表 来设置。
1 | System.out.println(System.getProperty("file.encoding"));//UTF-8 |
根据上面的程序发现,getBytes确实是根据file.encoding 来编码的, 下面我们修改一下file.encoding,再测试
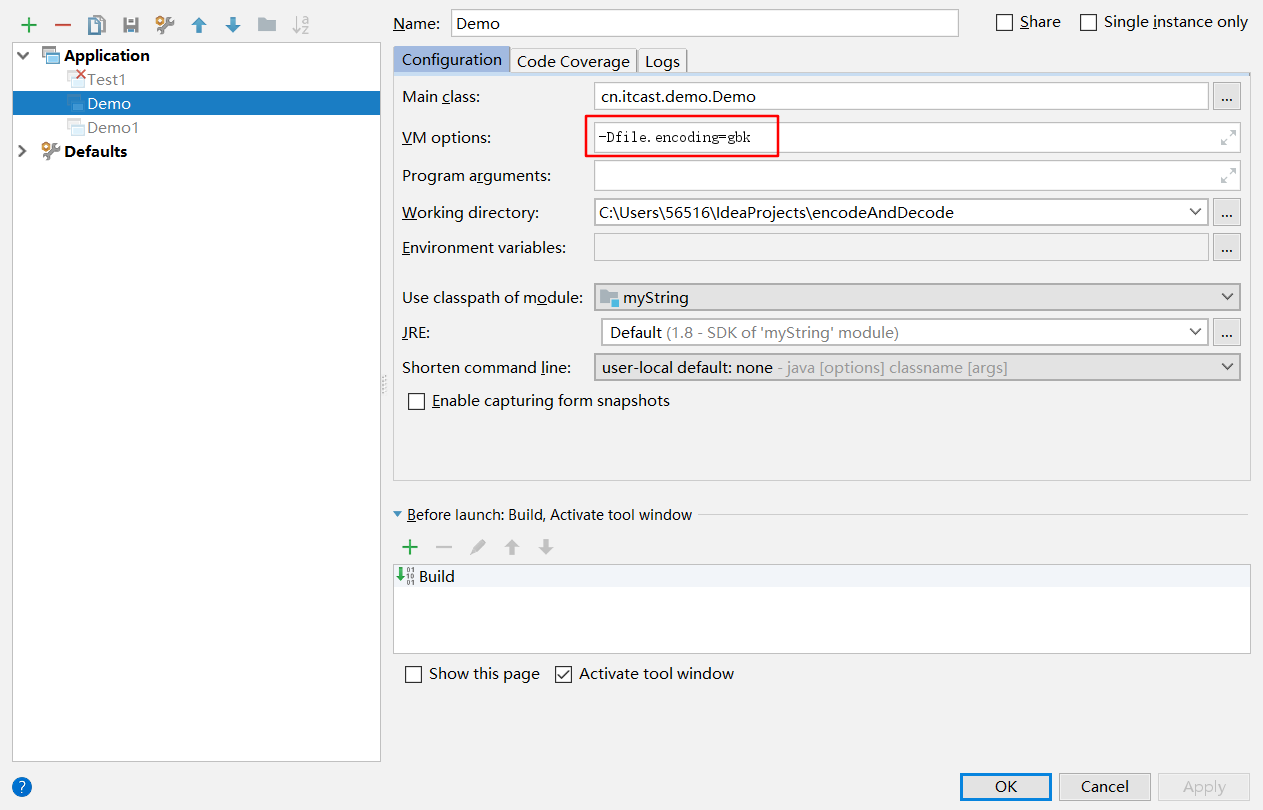
1 | class Demo{ |
根据结果,我们发现 getBytes方法根据java命令运行时参数 file.encoding设置的编码表进行编码的。但是我们还不知道file.encoding的时候,也没有设置file.encoding,为什么使用的是UTF-8呢,因为IDEA的设置如下图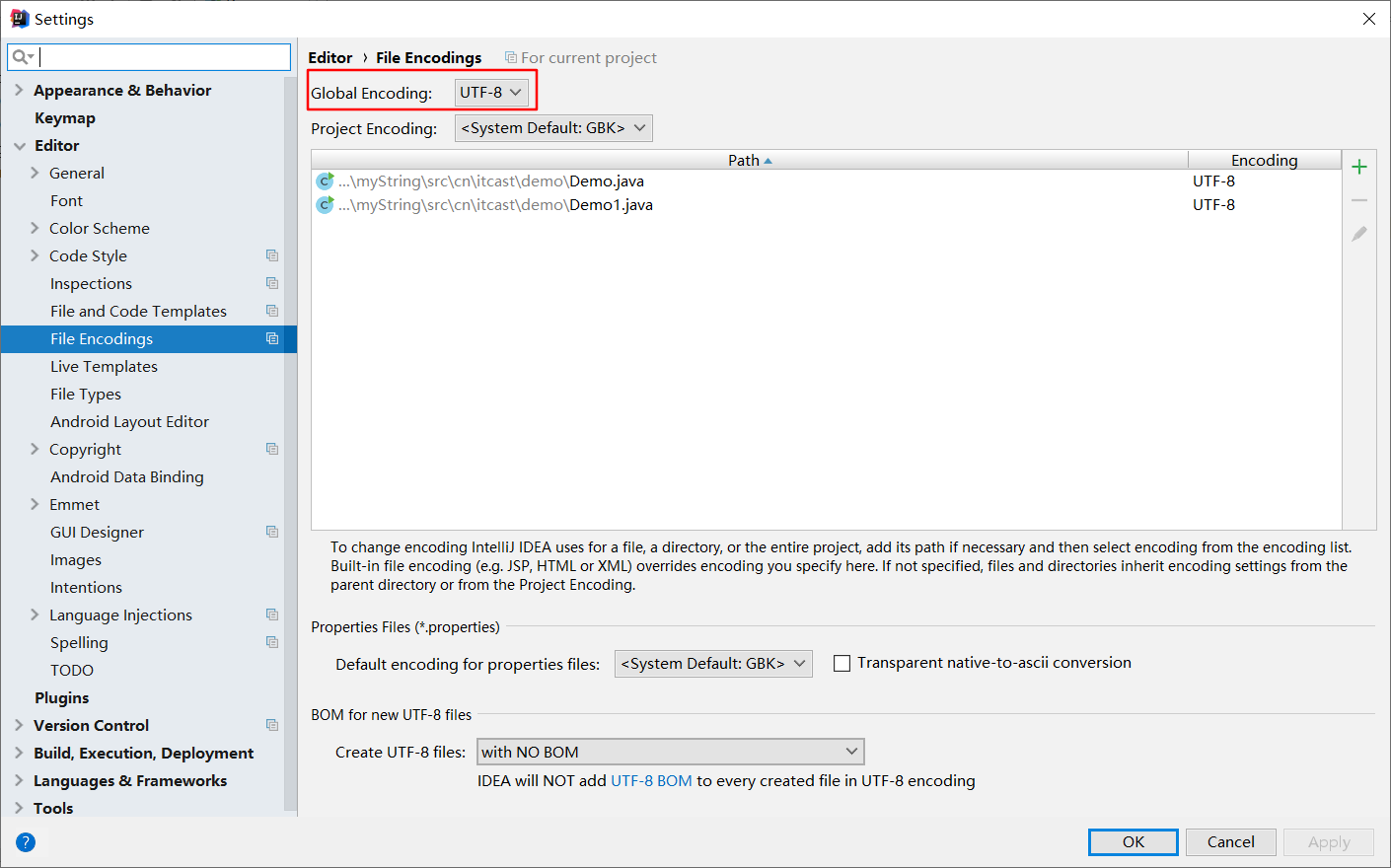
如果改变该编码为GBK,那么getBytes则使用GBK进行编码。
getBytes(String charsetName)方法
public byte[] getBytes(String charsetName); 此方法 根据指定的编码名称charsetName进行编码
1 | String s = "黑马"; |
解码的方法
String(byte[] code)
public String(byte[] code); 此方法根据file.encoding 进行解码
1 | String s = "黑马"; |
String(byte[] code,String charsetName)
public String(byte[] code,String charsetName); 此方法根据执行的码表名称 charsetName进行解码
1 | String s = "黑马"; |
乱码的情况
可逆的情况
1 | String s = "黑马"; |
不可逆的情况
1 | String s = "黑马"; |
1 | String s = "\uD842\uDFB7"; //𠮷 的Unicode码值 |
1 | String s = "♠"; |
ISO-8895-1编码的妙用
这也是为什么tomcat使用ISO-8859-1编码的原因。
1 | String s = "黑马"; |
1 | String s = "黑马"; |
IO流-字符流
InputStreamReader
正常
1 | InputStreamReader isr = new InputStreamReader(new FileInputStream("myString\\a.txt"),"UTF-8"); // 使用UTF-8编码读取a.txt文件 // a.txt 文件的编码格式是 UTF-8格式, 里面的内容是"中国"; |

乱码
1 | InputStreamReader isr = new InputStreamReader(new FileInputStream("myString\\a.txt"),"GBK"); // 使用GBK编码读取a.txt文件 |

OutputStreamWriter
正常
1 | OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream("myString\\a.txt"),"UTF-8"); //打开a.txt 不乱码 |

乱码
1 | OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream("myString\\a.txt"),"GBK"); |
复制文件
字符流复制文本乱码因素
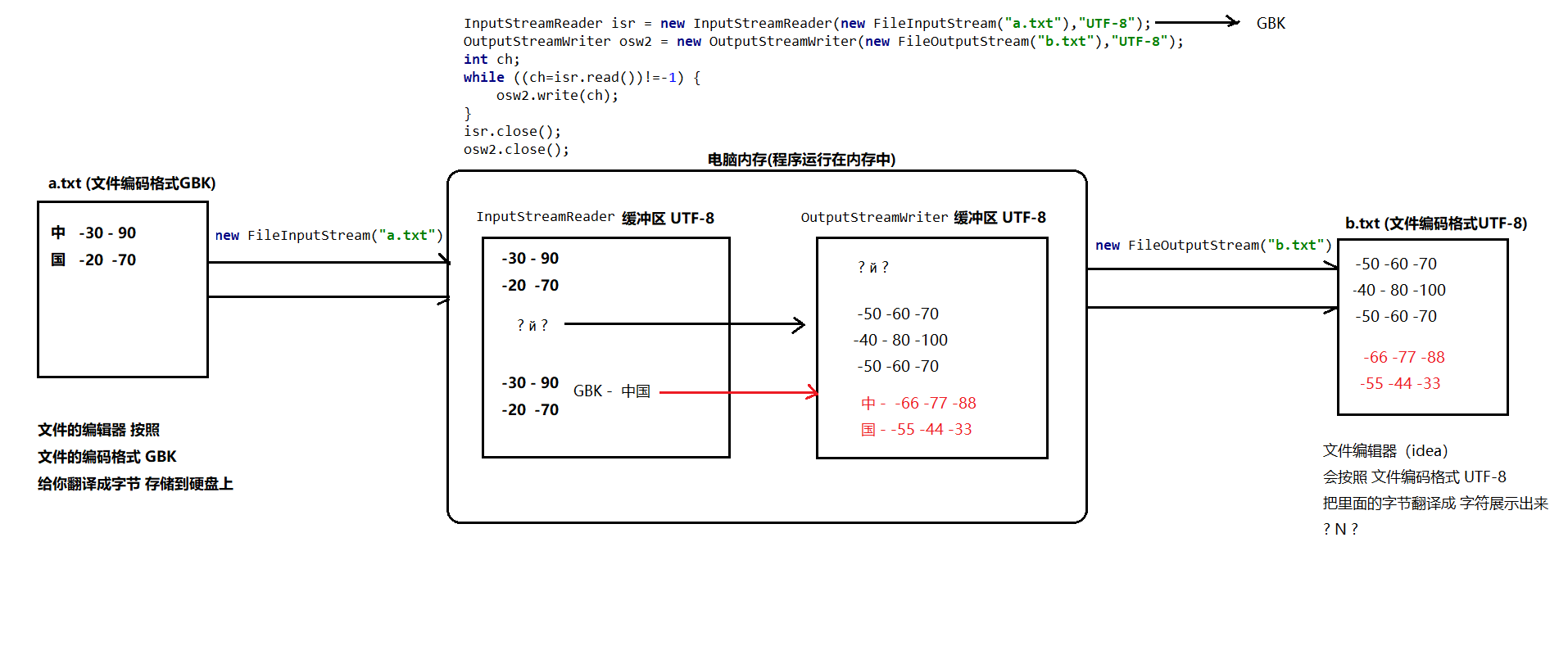
4个因素 源文件编码 Reader缓冲区编码 Writer缓冲区编码 目标文件编码,其中 源文件编码 和Reader缓冲区编码需要一致, Writer缓冲区编码 和 目标文件编码 需要一致。
1 | InputStreamReader isr = new InputStreamReader(new FileInputStream("d:\\b.txt"),"UTF-8"); // b.txt的GBK编码格式的 b.txt里面的内容是“中国” |
字符流UTF-8 编码复制图片
复制完成后, 新的图片存储大小会变大,并且无法正常打开。
1 | InputStreamReader isr = new InputStreamReader(new FileInputStream("d:\\1.jpg"),"UTF-8"); //1.jpg 是15.3kb 能正常打开 |
%E5%A4%8D%E5%88%B6%E5%9B%BE%E7%89%87%E5%8F%98%E5%A4%A7%E7%9A%84%E5%8E%9F%E5%9B%A0.png)
ISO-8859-1的妙用
使用ISO-8859-1编码的字符流复制文件,可以原样复制成功,并且可以正常打开。
1 | InputStreamReader isr = new InputStreamReader(new FileInputStream("d:\\1.jpg"),"ISO-8859-1");//1.jpg 是15.3kb 能正常打开 |
%E5%A4%8D%E5%88%B6%E6%96%87%E5%9B%BE%E7%89%87%E6%88%90%E5%8A%9F.png)
tomcat之所以使用ISO-8859-1编码,就是因为上面这个原因。